
machine learning
- Published on
- minor cyber body of knowledge · 10 min read
Machine Learning
Introduction
I would like to learn how to apply "Machine Learning" to data and thereby perform a useful analysis on this data. I would like to learn this as a new challenge to learn more about the techniques behind Machine Learning. What is it, what is it used for or when to use it. I am going to link to Cyber by performing a data analysis on a dataset related to the subject of cyber. In doing so, I am using the "Eron" dataset which is specifically used for forensics. In order to apply all of this, I need to learn about the different types of algorithms out there. For this I need Python and knowledge of the types of algorithms out there and when to apply them. By executing and following course on Udacity and the associated assignments, I am going to make this learning goal measurable for myself. Furthermore, I also want to eventually be able to perform an analysis on the Enron dataset.
Evaluate
Version (1)
Currently I am working on Udacity: "Intro to Machine Learning". This course I have now 50% completed. During this course I learned about Naive Bayes, SVM, Decision Trees and Regression. The material was easy to understand but at the moment I do not know how I can apply it within my own project/research. The step from theory to practice
Version (2)
Here I have been working on building an algorithm that detects gibberish. This was quite difficult because I had no prior knowledge. I contacted lecturer Peter Lambooij and discussed how I could best approach this. He suggested that I delve further into Naive Bayes. I had a small knowledge of Naive Bayes from the Udacity course but to build the algorithm I needed more knowledge so I decided to delve further into this subject. After finding out how the algorithm works and its applications I started to build a prototype. After the prototype, I built a final version whose elaboration is described below. Describing the elaboration was difficult because the prepairing of the data was quite complicated.
Assignments
Enron Dataset
The Enron Email Corpus is a massive dataset, containing approximately 500,000 messages from executives of the Enron Corporation. Enron was a large American company that was investigated by the Federal Energy Regulatory Commission (FERC) in 2001 after its rather spectacular bankruptcy and dissolution. It contains records of about 150 users, mostly management of Enron, organized in folders. The corpus contains a total of about 0.5M messages. This data was originally made public, and put on the web, by the Federal Energy Regulatory Commission during its investigation. In its raw form, the Enron corpus is a massive collection of folders containing 2.2 Gigabytes of messages in MBOX format, all individually preserved
Biggest corporate fraud
But first we need to know something about the biggest corporate fraud in American history! The Enron fraud is a big, messy, and totally fascinating story of corporate malfeasance of almost every type imaginable. Although it started out as an energy company, it was involved in so many complex issues that people didn't understand exactly what the company was doing. Enron was fantastic! Very attractive to investors and the fastest growing company that was making money at a rate no one had ever seen. They were the darlings of Wall Street, a company that could never lose. It had good political connections, was making money at an incredible rate, and seemed to be the leading innovative company and highly profitable investment.
In the course I will be taking, we are going to use Python to analyze the dataset, and discover patterns and clues through data exploration, as well as build a regression model that could predict the bonus of a person at Enron based on the salaries he receives.
recourse:
Analysis on enron mail datasets
Analysis on enron mail datasets:
| Question | answer |
|---|---|
| How many data points (people) are in the data set? | 146 |
| For each person, how many functions are available? | 21 |
| How many POIs are there in the E+F dataset? | 18 |
| How many POIs are there in total? | 35 |
| What is the total value of James Prentice's shares? | 1095040 |
| How many emails do we have from Wesley Colwell to persons of interest? | 240 |
| What is the value of stock options exercised by Jeffrey K Skilling? | 19250000 |
| Who made the most money? | YEAP SOON |
| How many people in this dataset have a quantified salary? | 95 |
| How many people in this dataset have an email address? | 111 |
| How many people in the E+F dataset (as it currently exists) have "NaN" for their total payments? | 21 |
| What percentage of people in the data set as a whole do? | 14.38% |
| How many POIs in the E+F dataset have "NaN" for their total payments? | 0 |
| What percentage of POIs as a whole is this? | 0% |
learning objectives
The assignment above here elaborate the following learning objectives from body of knowledge:
- Study forensic methodologies and practices (see resources below). List these standards and how and where they are applied in your portfolio or in a blog or article.
- Work out forensic challenges that you can find online or get from teachers.
Gibberish detection - naive bayes
For the project where I had to analyze and conclude a hypothesis, I created a Machine Learning algortime by applying Naive Bayes. Hereby I prepared different dataset and merged them.
The datasets used for this purpose consist of:
| Dataset | Description | Label |
|---|---|---|
| Amazon Reviews | Top review left under a product by customers | Positive (1) |
| Youtube Cyptic comments | Spam comments left by users under videos | Negative (0) |
| Gibberish | A dataset with random characters | Negative (0) |
I labeled this dataset with code and made it usable for analysis. To apply Naive Bayes, I used scikit-learn. Naive Bayes is a method for calculating the probability of something happening. In the project, I use this because I want to calculate the probability that text is positive or negative in nature. The probability is calculated by analyzing the dataset and attaching weights to it. For example, how often does a specific word occur in a text. Let's use the words "dog," "toy," "brown," and "sunny" as examples. Suppose the analysis shows that the word dog occurs as many as 100 times and the other words also occur around that range. Then we add a dataset with the characteristics of gibberish language. Weights are also attached to this. Now when we continue to make a prediction of the word "sun" it will always be positive. But if we are going to predict the word "adskladhjl" it will be negative.
So to get this done we need to start training the algorithm below is an example of this.
# Count word usage
vectorizer = CountVectorizer(stop_words='english')
all_features = vectorizer.fit_transform(df_merged.Response)
# Split list into random train and test subsets
x_train, x_test, y_train, y_test, = train_test_split(all_features, df_merged.Label, test_size=0.35)
classifier = MultinomialNB() # Create Model (naive bayes) multinomial
classifier.fit(x_train, y_train) # Train Model
In my code, I use the multinomial Naive Bayes classifier.
This is suitable for classification with discrete features (e.g., word counts for text classification)
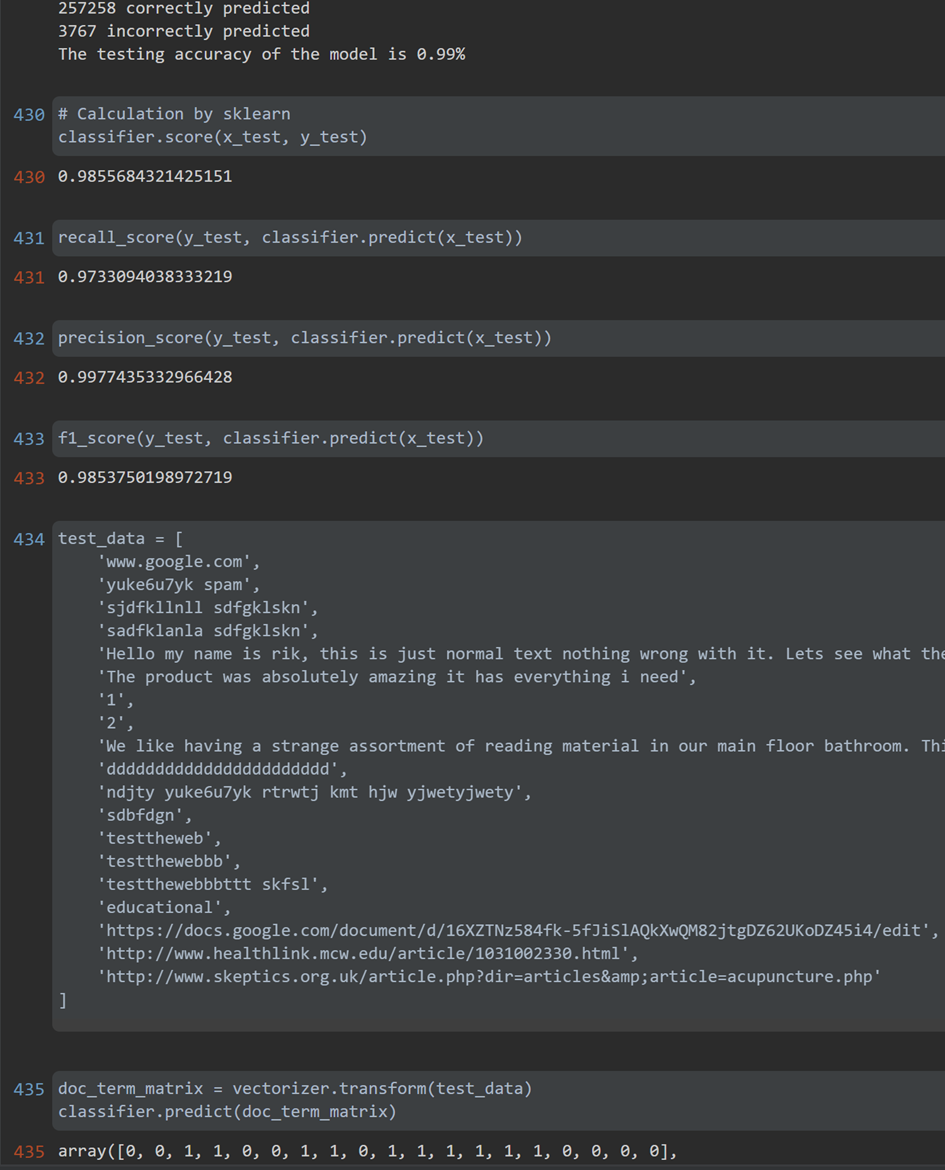
It is very important for an algorithm that the accuracy is high. From the image above you can see that my algorithm can make a prediction for future data with a certainty of around 98%.
Workshop Tilburg
During this workshop it was explained how machine learning could be applied to detect cyber attacks. Here we were given a presentation with the basic principles and techniques. We were then allowed to apply these within the supplied dataset. Because I already did two projects within this field it was not so difficult and it was easy because they used scikit learn.
Confusion Matrix
When you are using machine learning algorithms it is useful to always test your dataset. This can be done with a confusion matrix when done you can see where your algorithm goes wrong and where it predicted wrong values. It gives you a general performance level of a classification model.
Below I am going to briefly explain how to read a confusion table:
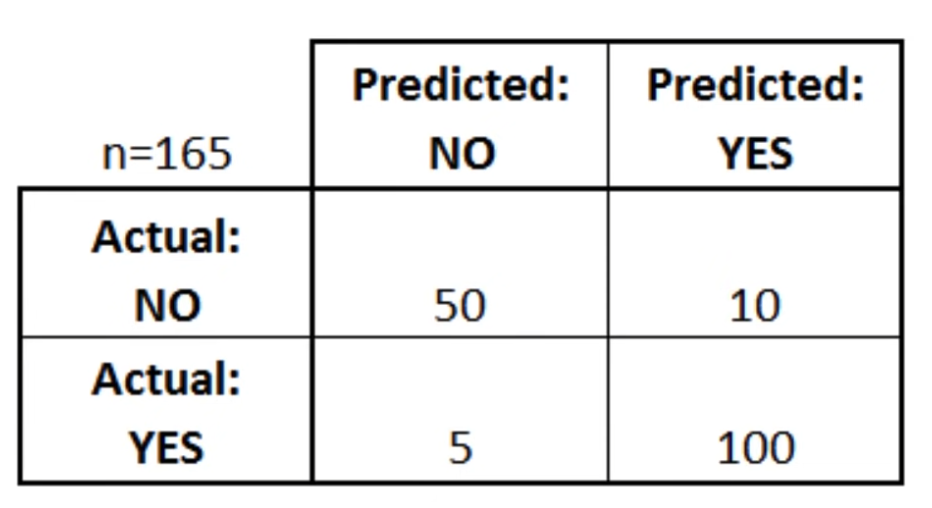
as you can see the total predictions that this model did was 165. Within those 165 predictions it gave a total of 100 times yes when it was actually yes and it predicted no 50 times when it was actually no. But we can also see the errors we can for example see that it predicted no 5 times when it was textually yes and 10 times yes when it was actually no.
- 50 times No when it was actually no = true negatives
- 100 times yes when it was actually yes = true positives
- 5 times no when it was actually yes = true positives = type two error
- 10 times yes when it was actually no = false positives = type one error
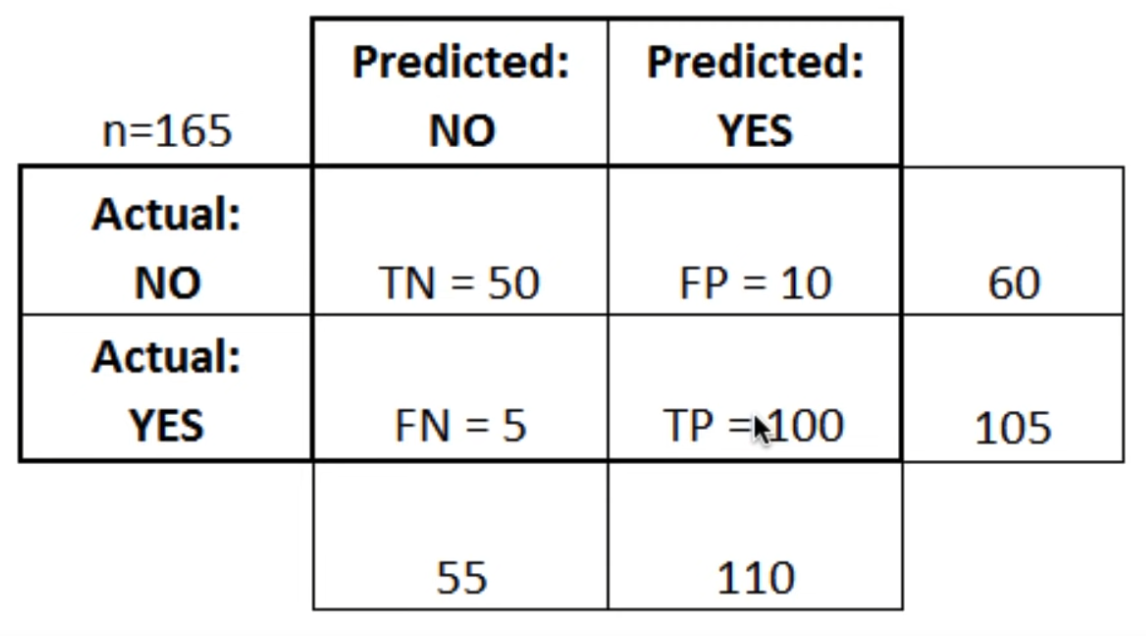
This is a list of rates that are often computed from a confusion matrix:
-
Accuracy: Overall, how often is the classifier corrrect?
- (TP+TN)/total = (100+50)/165 = 0,91
-
Misclassification Rate (Error rate): Overall, how often is it wrong?
- (FP+FN)/total = (10+5)/165 = 0.09
-
True Positive Rate: When it's actually yes, how often does it predict yes?
-
TP/actual yes = 100/105 = 0.95
Also known as "Sensitivity" or "Recall"
-
-
False Positive Rate: When it's actually no, how often does it predict yes?
- FP/actual no = 10/60 = 0.17
-
True Negative Rate: When it's actually no, how often does it predict no?
-
TN/actual no = 50/60 = 0.83
Equivalent to 1 minus False Positive Rate
Also known as "Specificity"
-
-
Precision: When it predicts yes, how often is it correct?
- TP/predicted yes = 100/110 = 0.91
-
Prevalence: How often does the yes condition actually occur in our sample?
- actual yes/total = 105/165 =0.64
Below is a confusion matrix I made at the workshop in tilburg:
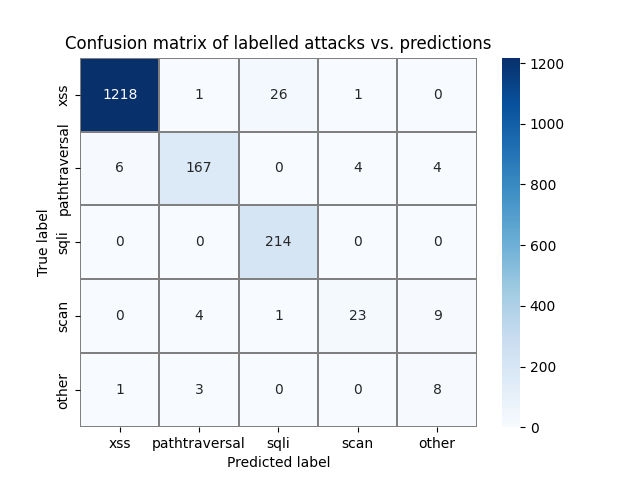
Here we can see that the table is bigger but the same principle remains.
Thank you for reading this topic about machine learning I hope it was interesting any feedback is always welcome. Hope to see you in the next topic,
Byee! 👋🍺
TL;DR A project where I apply machine learning to the aspect of cyber. Here I am using techniques such as naive bayes for label detection in a dataset