DevOps practices in Flowcontrol
- RESEARCH REPORT
- Grozdev,Stoyan S.G.
- 21/08/2024
Introduction
During my third-year internship at Fontys HBO-ICT, which spanned five months at Limax B.V. in Horst, I had the opportunity to collaborate closely with the software development team on the Flowcontrol system. Limax B.V., part of the Limax Group, operates in the agribusiness sector with a focus on mushroom cultivation and trading in the Netherlands and Poland. My internship was primarily focused on optimizing the Continuous Integration/Continuous Deployment (CI/CD) pipeline for Flowcontrol, a sophisticated microservices-based web application designed to digitalize and optimize Limax's business processes.
The primary objective of my internship was to enhance the CI/CD pipeline of Flowcontrol to align it with industry standards, ensuring more efficient, secure, and reliable software delivery. The CI/CD pipeline, structured around Continuous Integration (CI) actions triggered by push or pull requests to the "dev" branch, and Continuous Deployment (CD) actions triggered by pull requests to the "master" branch, faced several challenges that needed addressing. Additionally, I integrated Kubernetes into the deployment process to improve the orchestration and management of the microservices, ensuring the system's scalability and resilience.
Key Contributions
Self-Hosted Runners Maintenance: I implemented a cron job for regular maintenance to address the issue of self-hosted runners being deleted after 14 days of inactivity. This ensured that the runners remained active and up-to-date, significantly improving the reliability of the CI/CD pipeline.
Dependency Caching: By identifying frequently used files and integrating them into a caching system, I was able to reduce workflow execution times and costs. This optimization allowed for quicker builds and deployments, enhancing overall pipeline efficiency.
Reusable Workflows: I created reusable workflows within GitHub Actions to eliminate redundancy and simplify maintenance. This change promoted consistency across the CI/CD pipeline and made the workflows easier to manage and update.
Enhanced Security: I secured sensitive information by utilizing GitHub Secrets, ensuring that sensitive data such as API keys and credentials were protected from unauthorized access. This measure was critical in safeguarding the integrity of the CI/CD process.
Resource Optimization: To further streamline the CI/CD pipeline, I consolidated smaller jobs into unified tasks within the GitHub Actions workflow. This consolidation improved resource utilization and reduced the overall execution time of the pipeline.
Docker Compose Restructuring: I reorganized the Docker Compose files and their associated environment variables, storing them securely in GitHub Secrets. This restructuring contributed to a reduction in the CI/CD pipeline execution time from approximately 15 minutes to around 3 minutes.
Kubernetes Integration: I integrated Kubernetes into the deployment process, utilizing Minikube for local development and Helm charts for managing Kubernetes resources. This integration ensured that the microservices could be effectively orchestrated, scaled, and managed, enhancing the system's overall scalability and resilience.
Additional Focus Areas
Beyond the CI/CD pipeline optimization, I worked on enhancing the unit and integration testing frameworks within Flowcontrol. I developed additional unit tests for critical modules and optimized the use of integration tests to ensure thorough validation while managing resource use effectively.
I also focused on improving data consistency and service dependencies within the microservices architecture. This involved integrating custom validation logic into POJOs (Plain Old Java Objects) and extending these validations from the controller layer to the business logic layer, thereby enhancing data integrity and error handling across services.
Approach
Research
The research conducted during my internship at Limax B.V. was centered around optimizing the Flowcontrol system's CI/CD pipeline, with the ultimate goal of enhancing the speed, reliability, and efficiency of software updates. This research was guided by a primary research question, supported by several sub-questions, each addressing specific aspects of the CI/CD pipeline and its associated technologies.
Research Questions
Main Research Question:
- How can DevOps practices optimize the speed and reliability of software updates, improve product quality, maintain software stability, and reduce the operational cost of Flowcontrol?
Sub-questions:
- What practices can be used for CI/CD pipeline optimization for Flowcontrol?
- How do unit and integration tests each affect the efficiency and effectiveness of CI/CD pipelines in GitHub Actions, and what strategies can be employed to balance them for quicker deployments?
- How can integration testing be adapted to address the challenges of data consistency and service dependencies in a microservices architecture?
- What are the considerations for a successful Kubernetes deployment in this context, including configuration management, resource allocation and management, service discovery, and networking?
- What is the impact of Minikube, Docker Swarm, and Kubernetes (via Docker Desktop) on the development workflow of the Flowcontrol project?
- What are the advantages and challenges of maintaining two separate CI/CD workflows for Kubernetes and Docker?
Research Methodology
To answer these questions, a combination of methods was employed:
Interviews and Documentation Review:
- An initial understanding of the Flowcontrol system was gained through an interview with the main developer and a thorough review of the existing CI/CD pipeline documentation. This foundational step helped clarify the current state of the system and identify specific areas for improvement.
Technical Implementation and Testing:
- Practical solutions were implemented based on research findings. For example, a cron job was implemented to maintain self-hosted runners, and reusable workflows were introduced to streamline the CI/CD pipeline. Testing was conducted to ensure these changes effectively improved the system's performance.
Comparative Analysis:
- Various tools and strategies, such as Kubernetes, Docker Swarm, and Minikube, were evaluated to determine their impact on the Flowcontrol project's development workflow. This analysis informed decisions about which tools to integrate into the CI/CD pipeline.
Security Enhancements:
- GitHub Secrets were utilized to securely manage sensitive information within the CI/CD workflows, ensuring that the pipeline adhered to best practices in security and data protection.
Sub-Question 1: CI/CD Pipeline Optimization
Addressing Runner Inactivity in GitHub Actions
The current configuration of self-hosted GitHub Actions runners faces a significant challenge due to GitHub's policy of deactivating runners after 14 days of inactivity. This deactivation disrupts continuous integration and delivery (CI/CD) processes, causing interruptions in automated workflows and impacting development efficiency.
Initial Exploration and Solution
An initial exploration was made into using an automated workflow trigger to periodically activate the runners. However, difficulties were encountered in getting this approach to function reliably. As an alternative, the solution pivoted to using a cron job on an Ubuntu machine to run a daily maintenance script that restarts the runners, which has proven to be a more stable and effective approach.
Proactive Maintenance Strategy
To address this issue, a proactive maintenance strategy is required to ensure that the runners remain active and up-to-date. The solution involves implementing a cron job on an Ubuntu machine to trigger a maintenance script nightly, thereby maintaining the functionality of the runners.
Implementation Details
The first step involves recognizing the problem of runner inactivity. This issue necessitates a solution that can maintain continuous operation without manual intervention. To this end, a cron job has been scheduled to run daily at 2 AM. This timing is strategically chosen to avoid disruptions during working hours, ensuring that the maintenance tasks do not interfere with ongoing projects.
In the research to find the best way to stop and restart the runners, it was discovered that the most effective approach was to focus on the Runner.Listener process. The maintenance script, located at /home/flowcontrol/Desktop/runners/combined_restart_runners.sh, performs essential functions to keep the runners operational. The script is designed to stop all instances of Runner.Listener, ensuring that no processes are left running unintentionally.
Terminating Runner.Listener is crucial because it is the primary process responsible for handling the runner's communication with GitHub (GitHub Docs, n.d.; DEV Community, 2023). This approach ensures that any potentially problematic or stale runner instances are completely stopped. Alternative methods, such as simply restarting the runner service, might not address underlying issues caused by orphaned processes or incomplete terminations, leading to inconsistent runner states and potential security vulnerabilities (karimrahal.com, 2023).
Stability and Reliability
Following this, a 5-second sleep interval is incorporated to allow processes to terminate properly, which is crucial for system stability. Finally, the script sequentially restarts each runner, handling potential startup failures with error notifications to ensure that each runner is fully operational.
This whole process can be seen in the figure below:
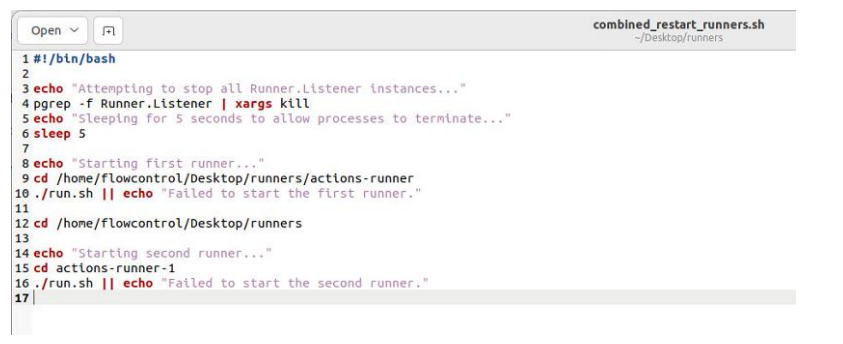 Figure 1: Script for restarting runners
Figure 1: Script for restarting runners
The implementation of this solution is straightforward. The cron job is added to the system's crontab file with the command crontab -e, and the following line is inserted to schedule the script to run daily at 2 AM. As it can be seen in the figure below:
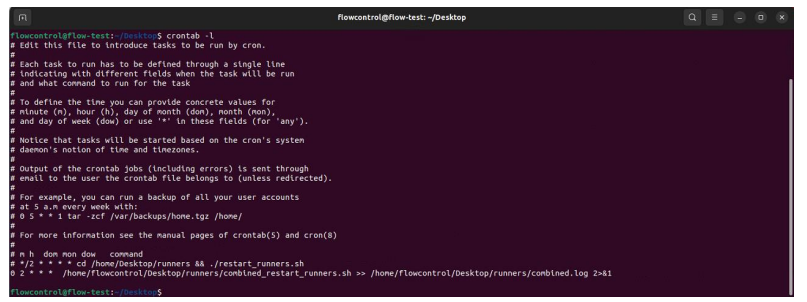 Figure 2: Cronjob
Figure 2: Cronjob
This setup ensures that the maintenance script is executed regularly, preventing runner deactivation due to inactivity.
By employing this cron job, the Ubuntu system ensures that self-hosted runners are regularly restarted, aligning with best practices for system maintenance. This approach enhances both security and operational integrity, eliminating the need for manual checks that can be error-prone and inefficient. The result is a seamless and efficient CI/CD pipeline that maintains continuous operation and security standards.
By employing this cron job, the Ubuntu system ensures that self-hosted runners are regularly restarted, aligning with best practices for system maintenance. This approach enhances both security and operational integrity, eliminating the need for manual checks that can be error-prone and inefficient. The result is a seamless and efficient CI/CD pipeline that maintains continuous operation and security standards.
2. GitHub Actions Cache
The current GitHub actions don’t use caching which is a strategy that speeds up workflow execution times and reduces cost by reusing files, like dependencies between jobs and workflows. This method is particularly beneficial because jobs on GitHub-hosted runners start with a clean slate, necessitating the redownload of dependencies for each run. This not only increases network utilization but also extends the runtime and costs associated with running the actions (GitHub Caching, n.d.).
To solve this problem, first, the dependencies and files the workflow repeatedly uses will be identified. These are files like the project’s dependencies managed by package managers (e.g., npm, Maven, pip). Next, the 'actions/cache' action will be incorporated into the workflow. This action allows caching based on a unique key, reducing the execution time by reusing data. The path to where the cache will be stored needs to be defined, and for the context of the current application, the path will be something like ~/ .m2.
The following code snippet demonstrates how to set up caching for Maven packages: 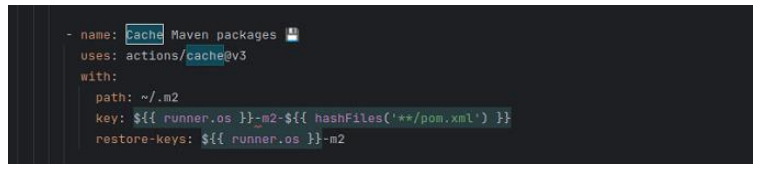
Figure 3: Cache set-up
When this is done and the code runs, there are two outcomes. The first one is when there is a cache hit, which means the key matches with the existing cache and the action restores the cached files to the path directory. The second one is when it doesn’t match, which is a cache miss, and a new cache is automatically created (GitHub Caching, n.d.). This process will improve the execution speed of the CI/CD.
3. GitHub Reusable Workflows
The current GitHub Actions setup does not use reusable workflows. This omission leads to workflow redundancy, where similar or identical jobs are replicated across multiple workflow files, increasing the complexity and potential for errors. Furthermore, this redundancy goes against the DRY (Don't Repeat Yourself) principle. By implementing reusable workflows, abstract common sequences of jobs can be made into a single, reusable component, streamlining the workflow (Reusable workflows, n.d.).
To address this, the initial step involves identifying common tasks or sequences within existing workflows that are candidates for modularization. These tasks often include setup procedures, build processes, testing routines, and deployment mechanisms that recur across multiple workflows (Reusable workflows, n.d.).
Upon identifying these commonalities, the next action is to abstract these tasks into standalone, reusable workflows. GitHub Actions facilitates this through the 'workflow_call' event, allowing workflows to invoke other workflows as if they were actions. This abstraction not only reduces the number of lines of code but also centralizes the logic, making updates and maintenance simpler and more consistent (Reusable workflows, n.d.).
Implementing reusable workflows requires defining them in dedicated YAML files within the .github/workflows directory. Each reusable workflow specifies its own triggers (on: workflow_call), inputs, and outputs. For example, a build process can be encapsulated into a reusable workflow, parameterized to accept different runtime environments or build configurations, and then called by other workflows with the specific parameters needed for each context (Reusable workflows, n.d.).
As shown in Figure 4, the reusable workflow is defined with the 'workflow_call' event and specifies required inputs such as the working_directory. 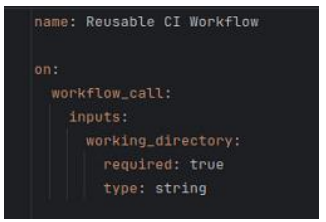 Figure 4: Example of a reusable CI workflow defined in a YAML file.
Figure 4: Example of a reusable CI workflow defined in a YAML file.
When integrating the reusable workflow into the CI/CD pipeline, the calling workflow uses the 'uses' keyword, specifying the path to the reusable workflow and passing any necessary inputs. This setup drastically simplifies the calling workflow file, reducing it to a few lines of YAML that specify what reusable workflows to run and with what parameters (Reusable workflows, n.d.) as illustrated in Figure 5.
Figure 5: Example of usage of a reusable CI workflow in a YAML file.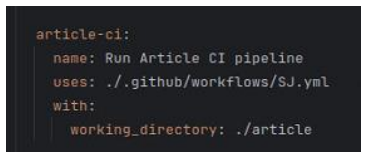
The outcomes of this approach mirror the benefits seen with caching: efficiency and cost-effectiveness. With reusable workflows, there is a significant reduction in the time and effort required to create, test, and maintain CI/CD pipelines. When a change is made to a reusable workflow, it automatically propagates to all workflows that use it, ensuring consistency and reliability across the entire software delivery process (Reusable workflows, n.d.).
4. GitHub Secrets
The current GitHub Actions do not use GitHub Secrets, a feature for safeguarding sensitive data such as passwords, private keys, and access tokens within CI/CD pipelines. GitHub-hosted runners are initiated from a clean state for each job, thereby requiring sensitive information to be securely passed each time a workflow is executed (GitHub Workflow syntax, n.d.-a).
To solve this, the initial step involves identifying all sensitive information and credentials that the workflow requires for operations such as accessing third-party services, deployment environments, or other secured resources. This information includes API keys, secret tokens, and configuration files that are crucial for the software's build and deployment processes managed by various services (e.g., AWS, Docker, NPM) (GitHub Workflow syntax, n.d.-a).
The second step is to integrate GitHub's 'secrets' into the workflow configuration. This feature securely stores and provides access to sensitive data, allowing it to be used within actions without exposing it in logs or to unauthorized users. Secrets are encrypted and only decrypted in the context of a workflow run, significantly reducing the risk of unauthorized access. For the context of the current application, secrets might include deployment credentials, API keys, or environment-specific configurations.
There are two types of secrets:
- Repository secrets: Used for sensitive data relevant to a single repository.
- Environment secrets: Used to store sensitive data that is different between various types of deployment environments like production, development, and staging.
To add a secret, navigate to the repository settings and access the 'Secrets' section, then click new repository/environment secret (GitHub Secrets, n.d.-b) as illustrated in figure 8.
The final step is to make the secret available to an action, and for that, the secret must be set as an input or an environment variable in the workflow file. This is done by referencing the secret in the .github/workflow YAML file using the ${{ secrets.SECRET_NAME }} syntax, where SECRET_NAME is the name of the secret previously configured in the setting (GitHub Workflow syntax, n.d.-a) as illustrated in the image below.
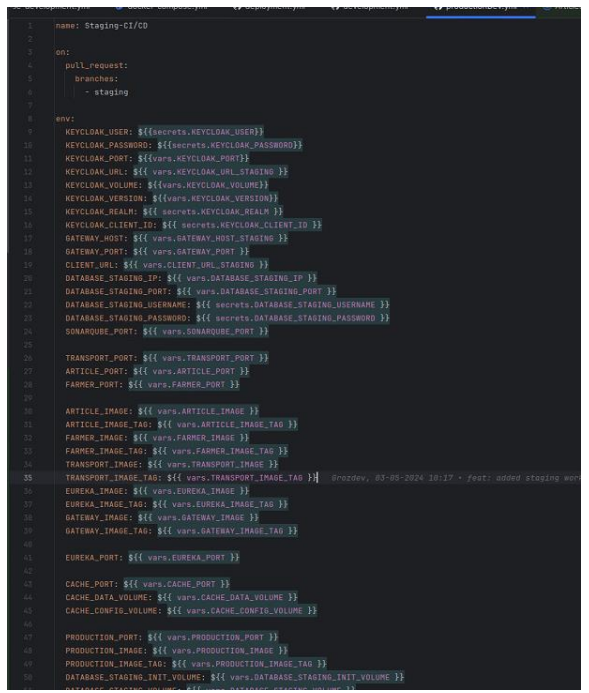 Figure 7: Applied GitHub secrets in the workflows.
Figure 7: Applied GitHub secrets in the workflows.
Figure 7 shows that all the environment variables were stored in GitHub actions and are called in the workflow from there. For example, the variable KEYCLOAK_USER gets the value from ${{ secrets.KEYCLOAK_USER }}.
5. Grouping Jobs
The current approach to manage small jobs in GitHub actions does not leverage the concept of grouping these tasks for optimized execution. This practice results in multiple discrete jobs being executed independently, which leads to increased billing due to the platform's per-minute billing structure (Danjou, J, 2023, October 3). The current approach goes against principles like DRY (Don't Repeat Yourself).
By applying a strategy that consolidates small, related jobs into a unified task, the workflow can be streamlined, mirroring the benefits of a reusable workflow (GitHub Workflow syntax, n.d.-a). To improve this, the first step is to identify small jobs that perform related or complementary functions within the CI/CD pipeline. These are tasks that are quick to execute but, when run separately, disproportionately consume resources due to the billing model's granularity.
Upon finding these opportunities, the subsequent action is to reorganize these small jobs into grouped tasks within the GitHub Actions workflow. The practical implementation of this strategy involves modifying the '.github/workflows' configuration to encapsulate the identified small jobs as steps within a larger job.
When integrating grouped jobs into the CI/CD framework, the process of configuring workflows is significantly streamlined. This streamlined configuration essentially involves specifying the grouped job alongside all required parameters and dependencies in a unified manner.
6. Docker Compose
These are the current Docker Compose files. Before delving deeper into what needs fixing, first the reason for the three separate Docker Compose files will be explained. 
Most of the time, there are three environments for an application's lifecycle. According to Karimyar (2023), Development is for building the software and, in this case, testing it in a local environment. Staging is used to test the software in a server setting where it mimics the production environment as much as possible. Then there is the Deployment (Production in this case) environment where the final version is deployed to users.
Having separate Docker Compose files for each of the environments helps manage dependencies and configuration specific to that stage, ensuring that code runs correctly before it reaches the end-user. The current Docker Compose files are messed up, and it cannot be understood which one is for which environment. Additionally, the .env variables are also in the same state, as it can be seen here:
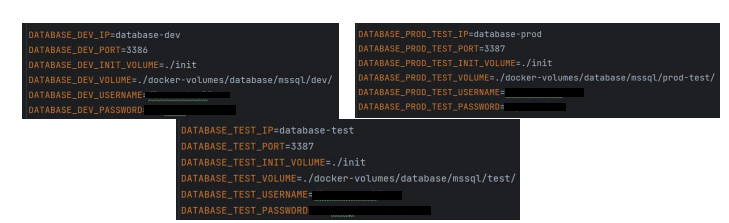
Now it will be explained how to solve these issues.
A solution for this problem is to clearly state and separate the environments and their environment variables. This includes renaming the current Docker Compose files and their variables. Also, these variables will be stored in GitHub Secrets and used in the Docker Compose files, as shown here:

Figure 6: Renamed Docker Compose files.
In Figure 6, the changes are shown. Now the Docker Compose files are more readable and understandable.
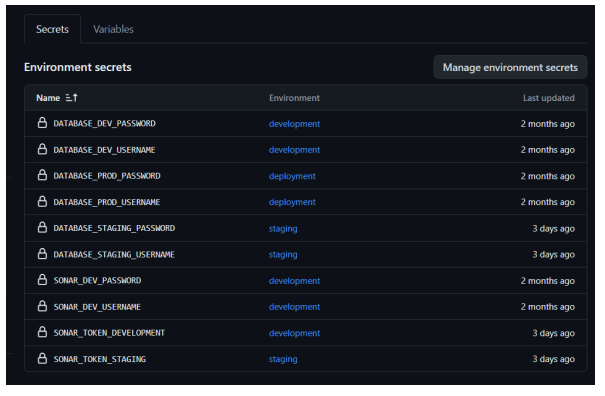 Figure 8: Github Secrets.
Figure 8: Github Secrets.
In Figure 8, the GitHub secrets can be seen and how they are set up. Each variable is assigned to an environment. In this project, there are development, staging, and deployment environments.
After implementing all of the changes, Figure 9 shows the final CI/CD workflow with the improvements:
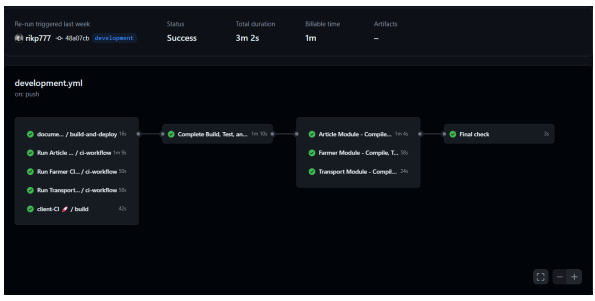
Figure 9: The improved CI/CD pipeline.
In the previous CI/CD setup, it took around 15 minutes to execute, and in the current one, it takes around 3 minutes, which is a noticeable improvement.
Sub-question 2: How do unit and integration tests each affect the efficiency and effectiveness of CI/CD pipelines in GitHub Actions, and what strategies can be employed to balance them for quicker deployments?
To address the question, it was first necessary to assess the current state of the entire project. This began with an examination of the project's existing tests, an interview with the main developer, Rik, and a review of the test suite. This review revealed that the project currently utilizes JUnit, Mockito, and Spring Boot Test as its primary testing frameworks. However, it was identified that not all modules are covered by unit tests, particularly for both happy and unhappy flow scenarios.
An example for this is the "ColorService" class and its associated "ColorServiceTest," which highlight both what is currently tested and what potential scenarios remain untested. For instance, while the "ColorServiceTest" effectively covers several happy flow scenarios such as retrieving colors by search keys, names, or IDs, and processing a mix of new and existing colors, it lacks tests for unhappy flow scenarios. These missing tests include handling queries that return no results, dealing with invalid input, responding to database or system errors, and managing empty or invalid data in bulk operations. Additionally, not each class has a unit test class set up, which can be seen in the two figures below. The "articleService" and the "caskService" don't have unit test classes, as well as other classes.
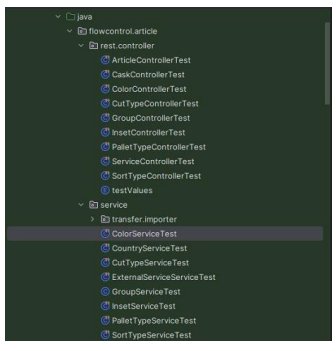 | 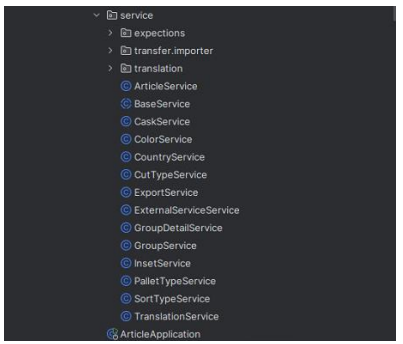 |
|---|---|
| Figure 10: The current unit tests | Figure 11: The service classes |
Following this initial project-wide assessment, the focus was specifically on the article module due to its high priority. To enhance the robustness and reliability of this crucial module, there is a clear need to develop additional unit tests for it. The target is to test for as many scenarios as possible for each method and test its proper behavior for the article module (Moradov, O 2022), ensuring comprehensive testing. Unit tests will follow the Arrange, Act, and Assert Pattern.
After analyzing the current situation, extensive research was conducted using both online resources and relevant books to understand how unit tests influence the CI/CD pipeline. This comprehensive approach provided insights that unit tests are vital for ensuring the functionality of individual components or modules within the application. They are lightweight and fast to execute and provide immediate feedback (BairesDev Editorial Team, n.d.). Integration tests, on the other hand, take a broader approach by verifying the interactions between different components. These tests require more time and resources, slowing down the CI/CD pipeline (BairesDev Editorial Team, n.d.).
To mitigate potential slowdowns in the CI/CD pipeline, a strategic approach will be adopted that focuses on running unit tests on every commit across all branches. This ensures that any code changes are immediately validated, allowing for rapid detection and correction of errors at the earliest possible stage in the development process. Unit tests, with their quick execution times, are ideally suited for this role, providing developers with instant feedback on the impact of their changes without significantly delaying the development cycle.
In contrast, integration tests will be reserved for the main branch only. This approach leverages the thoroughness of integration tests to ensure system-wide coherence and functionality before major updates or releases. By executing integration tests only on the main branch, resources are optimized, ensuring that these more extensive tests do not unnecessarily impede the continuous integration process on other branches. This targeted application of integration tests ensures that the CI/CD pipeline remains efficient, while still safeguarding the quality and reliability of the software in its final form.
Now it will be explained how each layer will be tested.
All testing within the business logic layer will be conducted with a focus on evaluating the behavior and application of business logic, rather than exploring database interactions or the specifics of how data is persisted. This approach, as detailed in "Unit Testing: Principles, Practices, and Patterns" by Vladimir Khorikov, stresses the importance of segregating business logic from orchestration. It advocates for a structured organization of code into distinct layers, specifically highlighting the critical role of the business logic layer in encapsulating the core functionalities and rules that define the application's behavior. This layer is distinguished from aspects such as data persistence or external communications, which are handled elsewhere in the architecture.
Unit tests within this layer are meticulously designed to verify the correctness and expected outcomes of the business logic, ensuring that operations like 'createOrUpdate' are rigorously tested for their functional integrity. This rigorous testing ensures that the business logic layer's operations are accurately validated against their intended outcomes, without being conflated with database or external dependencies, thus maintaining a clear focus on the application's core business processes and rules.
It's important to note that the testing of the repository layer will not be pursued through direct unit testing. Instead, the repository layer's functionality will be evaluated as part of the comprehensive integration testing conducted during the controller tests. This decision is informed by insights from "Unit Testing: Principles, Practices, and Patterns" by Vladimir Khorikov, which elucidates the challenges and diminished returns of directly testing repositories.
According to Khorikov, testing repositories separately from the integration tests may seem advantageous to validate how repositories map domain objects to the database. However, such an approach is ultimately counterproductive due to the high maintenance costs and limited benefits in preventing regressions. Repositories, by nature, exhibit minimal complexity and primarily interface with the database, an out-of-process dependency. This interaction significantly increases the maintenance costs of testing, without offering commensurate advantages.
Furthermore, the protective benefits against regressions offered by testing repositories overlap considerably with those provided by comprehensive integration tests, making separate repository tests redundant and not value-adding. Khorikov suggests that a more effective strategy involves abstracting any complexity within repositories into distinct algorithms and focusing the testing effort on these algorithms. This approach circumvents the pitfalls of high maintenance costs and enhances the test suite's efficiency by avoiding direct testing of repositories, which might not yield significant insights or benefits.
Thus, in alignment with the guidance from "Unit Testing: Principles, Practices, and Patterns," the repository layer will be indirectly tested within the scope of integration tests for controllers.
Now the improvements will be explained.
As illustrated in the figure below, each class now has unit test coverage, which was not the case previously.
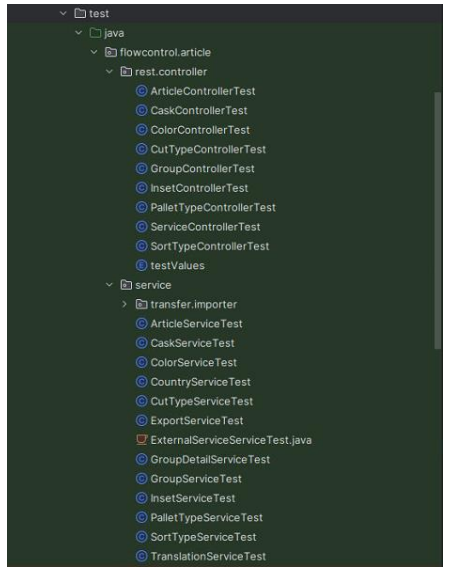
Figure 10: The unit tests after implementation.
And now moving to the next aspect.
The current project setup does not support the selection of specific test types. As of the time of the internship, the configuration is set to disregard the results of unit tests, marking them as successful regardless of their actual outcome. This means that even if the pipeline is configured to trigger integration and unit tests on specific branches, it will not affect the overall speed of the pipeline.
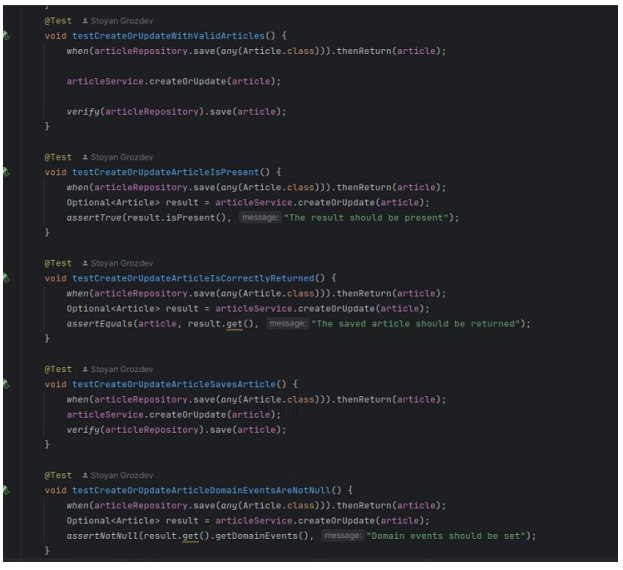
Figure 11: Example of the unit tests in the article class.
The Java test methods depicted in figure demonstrate the applied unit testing approach focused on the business logic layer, aligned with the principles discussed in "Unit Testing: Principles, Practices, and Patterns" by Vladimir Khorikov. This method separates the concerns of business logic from database interactions, emphasizing the importance of segregating these aspects to enhance test clarity and effectiveness. Here's a coherent breakdown for the figure:
testCreateOrUpdateArticleIsPresent(): This test checks that the "createOrUpdate" function returns a non-empty result, asserting the responsiveness and reliability of the business logic when handling article updates or creations. It uses a mock ofarticleRepository.save()to simulate the database interaction, focusing solely on the logic layer's output.testCreateOrUpdateArticleIsCorrectlyReturned(): Here, the focus is on ensuring that the article returned by thecreateOrUpdatemethod matches the expected output. This test further isolates the business logic from the persistence layer by using mocked data, checking for correct behavior without actual data persistence.testCreateOrUpdateArticleDomainEventsAreNotNull(): This method tests that domain events are correctly set and not null following an operation, which is crucial for ensuring that business rules regarding domain events are adhered to. The test effectively checks the enforcement of these rules within the business logic, independent of how these events are handled or stored downstream.
Each of these tests is crafted to confirm specific functionalities and rules within the business logic layer without delving into the details of data persistence or external communications, which are handled in the integration tests. This approach not only streamlines the unit tests to focus on the core functionalities but also maintains a clear separation from the database interactions, thereby reducing the complexity and maintenance costs associated with direct database testing.
All of these changes improve the current testing methodology applied in the project and allow for a concrete understanding of how the classes should behave.
Sub-question 3: How can integration testing be adapted to address the challenges of data consistency and service dependencies in a microservices architecture?
To tackle the challenges of enhancing data consistency and managing service dependencies in Flow Control's microservices architecture, a comprehensive evaluation of the entire project was initiated. This process involved a detailed review of the existing codebase, engaging in discussions with Rik, the lead developer, and a deep dive into the data management practices across various services. The assessment underscored a significant need for robust data management practices, particularly focusing on secure data transmission and validation between services. Currently, the system's validation is primarily limited to the controller layer with validation specific for the controller layer, where basic input checks such as parameter existence, data types, and formatting are conducted to ensure data usability and safety.
Building on the validation implemented at the controller layer, it is crucial to extend these validation practices into the business logic layer. This layer handles more complex validations that are crucial for the integrity of business operations and are closely tied to the core functionalities of our services.
Now the differences between the validation will be shown.
Let's break down the differences in validation logic between the "BaseArticleRequest" class and one of the newly implemented "ArticleValidator" class, specifically highlighting how each handles similar validations.
This comparison will start with the pallet limit and the minimum pallet quantity. The "BaseArticleRequest" class validates "palletLimit" and "minimumPalletQuantity" individually using annotations for maximum and minimum values. The "palletLimit" is checked to be between 1 and 200, and the "minimumPalletQuantity" is checked to be between 1 and 199.
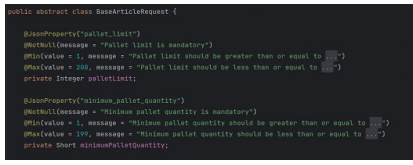
Figure 12: Validation of pallet limits in BaseArticleRequest.
In contrast, the "ArticleValidator" class validates "palletLimit" to be between 1 and 250, offering a wider range than the request class. The validator class does not specify a maximum for "minimumPalletQuantity" other than the maximum possible value for a Short. Additionally, "validatePalletRelationship" is used to ensure that "minimumPalletQuantity" does not exceed "palletLimit", a relational check that isn't directly possible through the annotations used in "BaseArticleRequest".

Figure 13: Relational validation between pallet limit and minimum pallet quantity in ArticleValidator.
Key difference is that the "validatePalletRelationship" is used to ensure that "minimumPalletQuantity" does not exceed "palletLimit", a relational check that isn't directly possible through the annotations used in "BaseArticleRequest".
The next example is UUID Validity and Entity Existence.
The "BaseArticleRequest" class validates each UUID field (e.g., typeId, groupId) either to be null or valid through "@UUIDNullOrValid". Furthermore, entity existence is validated in a second validation phase ("SequenceSecondOrder").
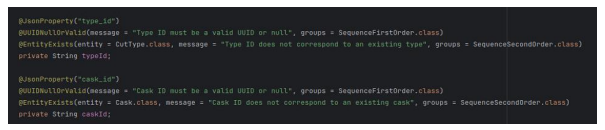
Figure 14: UUID validity and entity existence validation in BaseArticleRequest.
The "ArticleValidator" class performs explicit checks using methods like "validateNotNullAndUUID" and "validateUUID" for the validity of UUIDs.

Figure 15: UUID validity check in ArticleValidator.
The key difference here is the validator class provides more granular control over when and how UUID and entity existence validations are applied, allowing for more complex logic to be introduced easily.
In the efforts to bolster data integrity, based on recommendations from a mentor, POJOs (Plain Old Java Objects) such as ArticlePOJO, as seen in Figure 6, were introduced. The mentor's guidance was instrumental in focusing the research on the use of POJOs, underscoring their crucial role in ensuring that data transferred between services is both precise and secure, thereby minimizing risks of data corruption and unauthorized access. POJOs provide a structured framework for data exchange, enabling the transmission of only pertinent and properly formatted data, which significantly enhances data integrity (Georgiev, 2024). POJOs are simple data carriers used throughout an application to represent and manage data without the constraints of any framework, making them ideal for encapsulating business logic. DTOs (Data Transfer Objects), on the other hand, are specifically designed for transferring data efficiently between different layers or across networks, containing only necessary information to reduce the number of data transfers required. In this case, the class will be used as a POJO within a single class to encapsulate data and the business logic related to validating, without being used for data transfer between different layers.
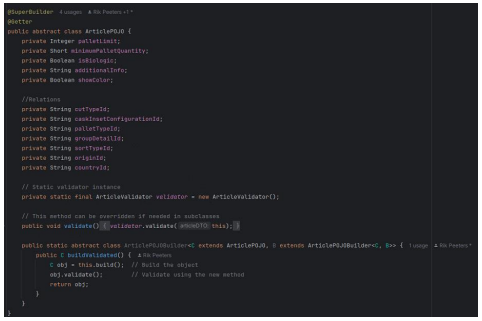
Figure 16: POJO structure.
The existing validation techniques proved inadequate for the complex business rules, necessitating the incorporation of custom validation logic within our POJOs. This integration facilitated granular control over the validation process, ensuring compliance with our specific business rules prior to any further data processing.
To effectively implement these strategies, as mentioned earlier, custom POJOs like ArticlePOJO, ArticleCreatePOJO, and ArticleUpdatePOJO were crafted to encapsulate all essential data attributes, thus ensuring data consistency and integrity. Furthermore, a custom validation framework was developed using BaseValidator<T>, which supported bespoke validation rules capable of adapting to complex data scenarios.
Figure 17 illustrates the base validation class, which serves as a foundation for other specific classes, allowing each to implement its own validation methods while inheriting common validation functionalities. This base class includes methods essential for validation applicable across all subclasses that extend it.
Figure 18, on the other hand, demonstrates how each extending class can customize these methods to cater to specific validation requirements, thereby enhancing the flexibility and specificity of the validation process.
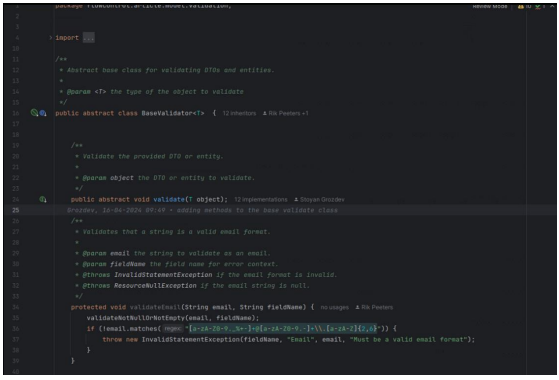
Figure 17: Base validation class.
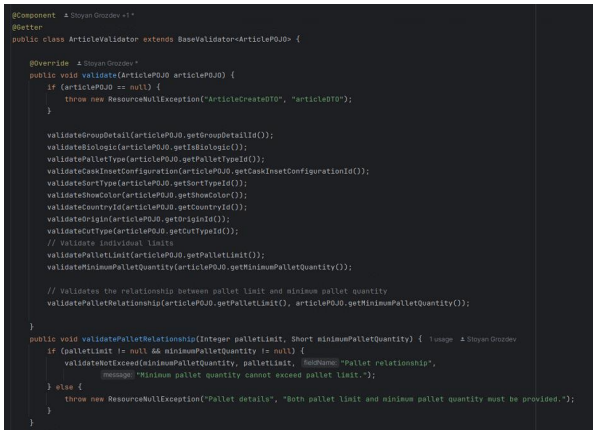
Figure 18: Article validation class.
Finally, the new POJOs were implemented in the mapper class where the entity mapping is done, as seen in Figure 19. At the end of the POJO, the custom method "buildValidated" is used instead of the normal "build". This approach ensures streamlined handling of data transformations between different layers of the application, maintaining the integrity and appropriate formatting of data. By isolating mapping logic from business logic, the architecture not only enhances error detection at an early stage but also simplifies debugging processes and increases the application's reliability and adaptability. This systematic enforcement of data rules through the mapper classes ultimately elevates the overall quality of data within the system (Chowdhury, 2024; Doe, n.d.).
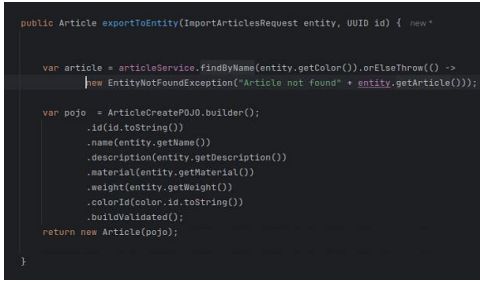
Figure 19: Validation implementation.
In addressing the challenges of data consistency and service dependencies in Flow Control's microservices architecture, a strategic shift was made to enhance integration testing. By integrating custom validation logic into our POJOs and extending validation practices beyond the controller layer into the business logic layer, we've achieved more robust data management. This approach not only ensures adherence to complex business rules but also improves error handling, significantly boosting the reliability and integrity of data across services.
Sub-question 4: What are the considerations for a successful Kubernetes deployment in this context, including configuration management, resource allocation and management, service discovery and networking.
Before starting to answer the question, it was necessary to assess the current situation. By talking to the main developer Rik, it was found out that the current project doesn't have Kubernetes set up nor does it use it. Rik also mentioned that for the purpose of this internship, he only wants a local installation of Kubernetes, as a proof of concept and to explore its potential benefits for the project.
To address the question and set up a local Kubernetes environment, it was first necessary to understand how to install and configure Kubernetes. This involved diving into YouTube tutorials like the one by TechWorld with Nana (2020) on Kubernetes for beginners and official Kubernetes documentation to gain the necessary knowledge. Following the guidelines, kubectl was installed as seen in Figure 20, the command-line tool for interacting with Kubernetes clusters, on the Ubuntu machine used as a staging machine in the company.
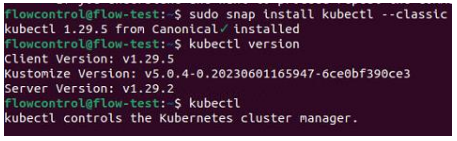 Figure 20: Installation of kubectl.
Figure 20: Installation of kubectl.
Next, the process proceeded to set up a local Kubernetes cluster using Minikube. The reason for choosing Minikube is that it is a tool that allows for the creation of a single-node Kubernetes cluster on a local machine, making it ideal for testing and development purposes. By using Minikube, a lightweight and isolated Kubernetes environment can be created without the need for a full-scale production cluster. This aligns with Rik's requirement of having only a local installation.
When considering the options for setting up a local Kubernetes cluster, several alternatives to Minikube are available, each with its unique features and potential drawbacks.
Docker Desktop is a popular choice for developers using Windows or macOS. It includes built-in Kubernetes support, making it easy to switch between Docker and Kubernetes environments. Docker Desktop is known for its user-friendly interface and cross-platform compatibility, which is ideal for collaborative projects and microservices architecture. However, it consumes more system resources compared to other solutions (Technical Ustad, 2022).
Kind (Kubernetes IN Docker) uses Docker container "nodes" to run local Kubernetes clusters. It's noted for its speed and simplicity, primarily serving testing and development needs. However, setting up Kind is more manual and involved compared to Minikube (Earthly, n.d.).
MicroK8s, developed by Canonical, is a lightweight Kubernetes option that installs easily and quickly, offering a minimal, self-contained Kubernetes for laptops and IoT devices. It's especially suitable for scenarios where resources are constrained. While MicroK8s provides a simple and fast setup, it has a steeper learning curve and less extensive documentation compared to Minikube (Earthly, n.d.; Rickard, 2022).
K3s is designed for resource-constrained environments and easy installation. It is a highly lightweight Kubernetes distribution, ideal for edge computing scenarios and situations where a full Kubernetes installation is an overkill. K3s strips down Kubernetes to the essentials, but this also means it lacks some of the features available in more comprehensive Kubernetes distributions (Earthly, n.d.).
Despite these alternatives, Minikube emerges as a suitable choice due to its balance of ease of use, resource efficiency, and broad compatibility across different operating systems. It provides a straightforward environment for learning and development without the complexity and resource demands of more extensive setups (Earthly, n.d.).
Each of these tools has its strengths and might suit different development needs. The choice would largely depend on specific project requirements, the environment in which the cluster is run, and personal or team preferences. In the context of this internship, Minikube aligns well with the main developer Rik's requirement of having a local installation for learning and exploration purposes. Its user-friendly interface, resource efficiency, and isolation capabilities make it an ideal choice for gaining hands-on experience with Kubernetes without the need for a full-scale production cluster.
By leveraging Minikube, a local Kubernetes cluster can be efficiently set up that serves as a foundation for exploring and validating the deployment of the application using Kubernetes. This local setup allows for gaining valuable insights into Kubernetes concepts and deployment patterns, aligning with best practices in the Kubernetes community. It provides a low-risk and cost-effective way to become familiar with Kubernetes, enabling informed decisions to be made about its potential adoption in development and deployment processes.
The figure below shows how Minikube was installed:
 Figure 21: Installation of minikube.
Figure 21: Installation of minikube.
After installing Minikube, the next step was to ensure that the existing Docker images could be used within the Minikube environment. This involved copying the Docker images from the local Docker daemon to Minikube's Docker environment. By doing this, it is ensured that the same images used during development can be leveraged within the local Kubernetes cluster. The Following figures shows the steps taken to do it.

Figure 22: Saving docker image to a file.
 Figure 23: Transfering the file to minikube with an abosolute path.
Figure 23: Transfering the file to minikube with an abosolute path.
 Figure 24: Loading the docker image into minikube.
Figure 24: Loading the docker image into minikube.
By specifying the absolute path /home/docker/flowcontrol-client.tar on the Minikube node, the tar file can be copied without encountering errors. Then, the image can be loaded into the Minikube Docker daemon as described (Minikube, 2023).
Continuing with the Kubernetes setup, the next step involves creating manifest files following the structure of Helm charts. Due to time constraints, not all modules have manifest files created. Helm, a package manager for Kubernetes, simplifies the deployment and management of applications. By organizing the manifest files in a Helm chart structure, managing and maintaining the various components of the application becomes easier.
The reason to use Helm is that it is particularly well-suited for microservices architectures like FlowControl for several reasons. Helm charts allow the definition, installation, and upgrading of complex Kubernetes applications. This modular approach enhances the modularity and reusability of configurations making it perfect to use for the micro architectural structure of Flowcontrol. Helm charts package Kubernetes resources such as deployments, services, and config maps into a single chart. This approach simplifies the deployment process by consolidating all Kubernetes manifests in one place, which proves useful for microservices with multiple configurations like flowcontrol(Moments Log, 2023; Microsoft Learn, 2023).
An example with the article module will be shown to illustrate this setup in the figure below.
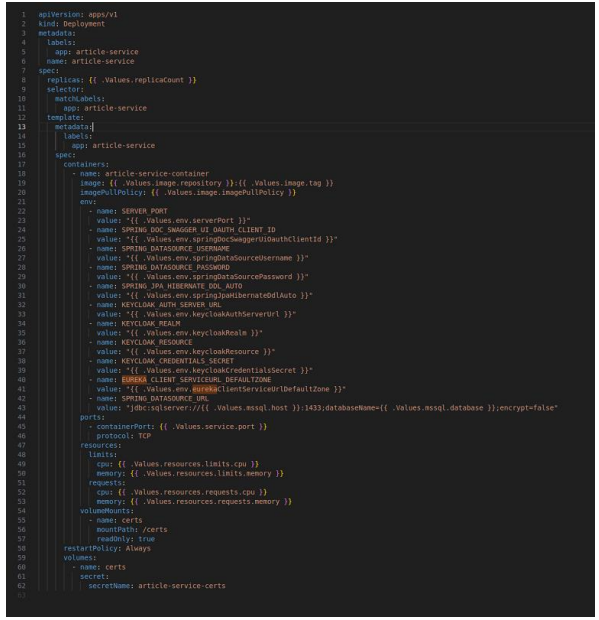 Figure 25: article-service yaml.
Figure 25: article-service yaml.
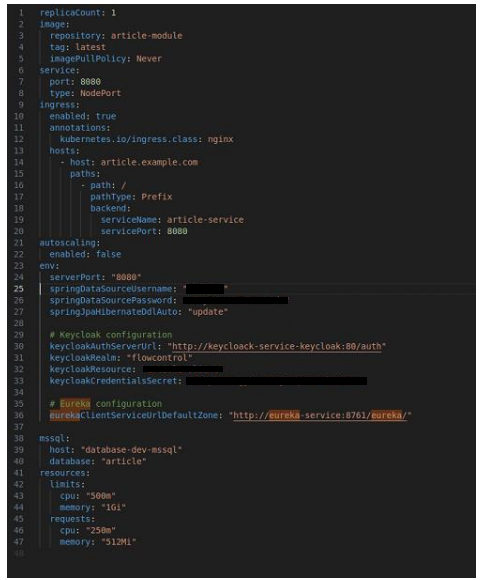 Figure 26: values for yaml for article-service.
Figure 26: values for yaml for article-service.
Figure 25 represents the deployment manifest for the article-service. This manifest file uses the values defined in the values file to create the necessary Kubernetes resources for deploying the article-service. It specifies the desired state of the deployment, including the number of replicas, container image, environment variables, ports, and volume mounts.
Figure 26 shows the values file for the article-service Helm chart. This file contains the configurable values used in the deployment manifest. It defines parameters such as the replica count, image repository and tag, service port, ingress settings, and resource limits.
In the current setup of the FlowControl project, ConfigMaps and Secrets are not being utilized for managing configuration values or sensitive information. Instead, the configuration values are directly specified in the Helm chart's values file, as shown in Figure 26. This approach is intentional and serves a specific purpose during the development and debugging phase of the project.
The decision to omit ConfigMaps and Secrets at this stage is primarily driven by the need for simplicity and flexibility while debugging the application. Having the configuration values readily available in the values file allows for quick modifications and testing without the overhead of managing separate Kubernetes resources.
By specifying the configuration values directly in the values file, settings can be easily changed, such as database connection details, Keycloak configuration, or Eureka service URLs, and redeploy the application to see the effects of those changes. This streamlined approach enables faster iteration cycles and simplifies the debugging process.
Furthermore, in a local development environment, the security concerns associated with storing sensitive information in plain text files are often less critical compared to production environments. The focus is to quickly test and debug the application without the added complexity of managing ConfigMaps and Secrets.
However, it's important to acknowledge that this approach is not suitable for production deployments. In a production environment, it is crucial to properly manage configuration values and secure sensitive information using ConfigMaps and Secrets. ConfigMaps are used to store configuration data separately from the application code, allowing for easier management and updates without modifying the deployment manifest. Secrets, on the other hand, are used to securely store and manage sensitive data, such as passwords, API keys, and certificates (Kubernetes Documentation, n.d.).
In the values file for the article-service (Figure 26), there is a section dedicated to resource configuration:
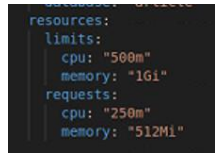
These values define the resource requirements and limitations for the article-service containers running in the Kubernetes cluster. Let's explore the reasons behind these specific values and provide some sources to support the explanation.
The specific values chosen for CPU and memory requests and limits in this example were provided by Rik, the company mentor, based on his experience and understanding of the article-service's resource requirements. While ideally these values should be determined through careful analysis, benchmarking, and performance testing of the application, Rik's guidance was relied upon in this case.
It's important to note that the values provided by Rik are not one-size-fits-all and may need to be adjusted based on the actual resource consumption patterns of the article-service. As the project progresses, monitoring and profiling the application's resource usage in different scenarios can help fine-tune these values for optimal performance and resource utilization.
Rik's expertise and familiarity with the FlowControl project's requirements played a crucial role in determining the initial resource configuration for the article-service. However, it is recommended to continuously monitor and assess the application's performance and make necessary adjustments to the resource requests and limits as needed.
In conclusion, the Kubernetes deployment setup for the FlowControl project has taken into account several important considerations to ensure a successful deployment in the local development context. These considerations include configuration management, resource allocation and management, service discovery, and networking.
Configuration management is handled by using Helm charts, which provide a structured and reusable approach to defining and managing the deployment manifests. The manifest files follow the Helm chart structure, allowing for easy organization and maintenance of the various components of the application. In the local development setup, configuration values are directly specified in the values file for simplicity and flexibility during the debugging phase.
Resource allocation and management are addressed through the specification of resource requests and limits in the values file. The specific values for CPU and memory requests and limits were provided by Rik, the company mentor, based on his experience and understanding of the project's requirements. These values ensure that the article-service containers have sufficient resources to perform their tasks while preventing resource overallocation. However, it is important to continuously monitor and fine-tune these values based on the actual resource consumption patterns of the application.
Sub-question 5: What is the impact of Minikube, Docker Swarm, and Kubernetes (via Docker Desktop) on the development workflow of the Flowcontrol project?
The introduction of Minikube and Kubernetes (via Docker Desktop) has streamlined the development workflow of the Flowcontrol project by enabling the creation and connection of manifests, despite the absence of a production setup and the use of only local development environments (Kubernetes.io, n.d.). This approach allows the project team to focus on writing code and building features, while Kubernetes handles the application's deployment and management in local development even though that the current implementation can't show that .
Minikube was chosen as the preferred tool for the Flowcontrol project due to its simplicity and ease of use. By creating manifests with Minikube in mind, the project team ensures compatibility and consistency with the intended deployment environment, even without setting up a local cluster (Minikube.sigs.k8s.io, n.d.). This approach saves time and effort in the development process, as it eliminates the need for a separate production environment setup.
The manifests created for the Flowcontrol project provide several benefits that enhance the development workflow. Firstly, they allow for a declarative definition of the application's components and resources, making it easier to understand and manage the application's structure (Kubernetes.io, n.d.). Secondly, the manifests ensure consistency between local development environments, reducing the risk of discrepancies and errors when collaborating within the team. Additionally, the manifests simplify the management of application dependencies and enable easy deployment and scaling in local development (Kubernetes.io, n.d.).
Kubernetes, accessed through Docker Desktop, is utilized in the development workflow to manage containerized applications. The created manifests serve as a blueprint for Kubernetes to manage application components, automate deployment and scaling, ensure high availability and fault tolerance, and simplify the management of application dependencies (Docker.com, n.d.). This integration of Kubernetes and manifests in the Flowcontrol project's development workflow has led to improvements in efficiency and reliability within the local development environment.
The decision to use Minikube and Kubernetes in the Flowcontrol project was based on their widespread adoption, community support, and feature set, which align with the project's goals and requirements (Zaira, 2019). Although Docker Swarm was initially considered, it was removed from the scope of the discussion, as Minikube and Kubernetes better suited the project's needs.
In conclusion, the introduction of Minikube and Kubernetes (via Docker Desktop) has streamlined the development workflow of the Flowcontrol project by enabling the creation and connection of manifests, providing benefits such as declarative definition of application components, consistency between local development environments, simplified management of dependencies, and future easy deployment and scaling. This approach allows the project team to focus on writing code and building features, while Kubernetes handles the application's deployment and management in local development, leading to improved efficiency and reliability
Sub-question 6: What are the advantages and challenges of maintaining two separate CI/CD workflows for Kubernetes and Docker?
The Flowcontrol project is currently evaluating the advantages and challenges of maintaining two separate CI/CD workflows for Kubernetes and Docker. Separate workflows offer flexibility, enabling the customization of each workflow according to the specific requirements and best practices of each platform. This flexibility allows for independent optimization of the workflows, ensuring that the unique features and capabilities of Kubernetes and Docker are fully utilized (Komodor, n.d.; Razorops, n.d.). Additionally, maintaining separate workflows promotes specialization, allowing for the development of expertise in each platform, leading to more efficient troubleshooting, faster issue resolution, and better performance optimization (Komodor, n.d.; Razorops, n.d.). Furthermore, separate workflows provide a degree of isolation between the Kubernetes and Docker environments, reducing the risk of widespread disruptions if issues arise in one workflow (Komodor, n.d.; Razorops, n.d.).
However, maintaining two separate CI/CD workflows also presents several challenges. Firstly, it increases the overall complexity of the project's CI/CD pipeline, making it more challenging to manage, monitor, and update the workflows, thus requiring additional time and resources (Komodor, n.d.; Razorops, n.d.). Secondly, having separate workflows may lead to duplication of effort in terms of configuration, maintenance, and troubleshooting, resulting in an increased workload and potential inconsistencies between the workflows (Komodor, n.d.; Razorops, n.d.). Thirdly, if the Kubernetes and Docker workflows need to interact or share resources, integrating the two workflows can be challenging, requiring additional development effort and careful planning to ensure smooth communication and data exchange (Komodor, n.d.; Razorops, n.d.). Lastly, maintaining separate workflows requires having a broad set of skills and knowledge covering both Kubernetes and Docker, making it more difficult to find individuals with the necessary expertise and potentially necessitating additional training (Komodor, n.d.; Razorops, n.d.).
It is important to note that the current setup of the Kubernetes workflow in the Flowcontrol project does not allow for thorough testing of the CI/CD pipeline. This limitation makes it challenging to ensure the reliability and efficiency of the Kubernetes workflow, potentially impacting the overall development process (Komodor, n.d.; Razorops, n.d.).
In conclusion, while maintaining two separate CI/CD workflows for Kubernetes and Docker offers advantages such as flexibility, specialization, and isolation, it also presents challenges like increased complexity, duplication of effort, integration challenges, higher skills and knowledge requirements, and limitations in the current Kubernetes setup. The Flowcontrol project must carefully consider these factors and weigh the benefits against the drawbacks to determine the most suitable approach for their specific needs and resources. Additionally, addressing the current limitations in the Kubernetes setup to enable pipeline testing should be a priority to ensure the effectiveness of the CI/CD workflow.
References
BairesDev Editorial Team. (n.d.). Integration Testing vs Unit Testing: Ensuring Software Reliability. Retrieved from https://www.bairesdev.com/blog/integration-testing-vs-unit-testing
Baeldung. (2024, May 11). Java bean validation basics. Retrieved from https://www.baeldung.com/java-bean-validation-basics
Chowdhury, I. (2024, April 25). Java object mapper: What, why, and how. Retrieved from https://www.learnwithih.com/blogs/java-object-mapper-what-why-and-how/
Danjou, J. (2023, October 3). Cutting Costs with GitHub Actions: Efficient CI Strategies. The Mergify Blog. Retrieved from https://blog.mergify.com/cutting-costs-with-github-actions-efficient-ci-strategies/
Docker.com. (n.d.). Kubernetes on Docker Desktop. Retrieved from https://www.docker.com/products/kubernetes
Doe, J. (n.d.). One-stop guide to mapping with MapStruct. Retrieved from https://reflectoring.io/mapping-with-mapstruct/
Earthly Blog. (n.d.). Comparing Local Kubernetes Development Solutions. Retrieved from https://earthly.dev
Georgiev, Z. M. (2024). SpringBoot DTO Validation — Good practices and breakdown. Paysafe Bulgaria. Retrieved from Medium. Retrieved from https://medium.com/paysafe-bulgaria/springboot-dto-validation-good-practices-and-breakdown-fee69277b3b0
GitHub Caching. (n.d.). Caching dependencies to speed up workflows. GitHub Docs. Retrieved from https://docs.github.com/en/actions/using-workflows/caching-dependencies-to-speed-up-workflows
GitHub Reusable workflows. (n.d.). Reusing workflows. https://docs.github.com/en/actions/using-workflows/reusing-workflows
GitHub Runners. (n.d.). About self-hosted runners. Retrieved from https://docs.github.com/en/actions/hosting-your-own-runners/managing-self-hosted-runners/about-self-hosted-runners
GitHub Secrets. (n.d.-b). Using secrets in GitHub Actions. Retrieved from https://docs.github.com/en/actions/security-guides/using-secrets-in-github-actions
GitHub Triggers. (n.d.). Events that trigger workflows. Retrieved from https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows
GitHub Workflow syntax. (n.d.-a). Workflow syntax for GitHub Actions. Retrieved from https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#jobsjob_idstepsenv
Karimyar, M. (2023, June 20). What's the difference between Production, Development and Staging Sites? ServerMania. https://www.servermania.com/kb/articles/production-development-staging
Khorikov, V. (n.d.). Unit Testing: Principles, Practices, and Patterns. Retrieved from https://dokumen.pub/qdownload/unit-testing-principles-practices-and-patterns-1nbsped-1617296279-978-1617296277.html
Komodor. (n.d.). CI/CD pipelines for Kubernetes: Best practices and tools. Retrieved from https://komodor.com/blog/ci-cd-pipelines-for-kubernetes-best-practices-and-tools/
Kubernetes. (n.d.). Command line tool (kubectl). Retrieved May 31, 2024, from https://kubernetes.io/docs/reference/kubectl/
Kubernetes.io. (n.d.). Declarative Management of Kubernetes Objects Using Configuration Files. Retrieved from https://kubernetes.io/docs/concepts/overview/working-with-objects/kubernetes-objects/
Kubernetes.io. (n.d.). Kubernetes Documentation. Retrieved from https://kubernetes.io/docs/home/
Microsoft Learn. (2023). Microservices CI/CD pipeline on Kubernetes with Azure DevOps and Helm. Retrieved from https://learn.microsoft.com/en-us/azure/architecture/example-scenario/apps/devops-with-aks
Minikube. (2023). Commands - cp. Retrieved from https://minikube.sigs.k8s.io/docs/commands/cp/
Minikube.sigs.k8s.io. (n.d.). Minikube Documentation. Retrieved from https://minikube.sigs.k8s.io/docs/
Moments Log. (2023). Scaling Microservices with Kubernetes and Helm Charts. Retrieved from https://www.momentslog.com/development/web-backend/scaling-microservices-with-kubernetes-and-helm-charts-2
Moradov, O. (2022). Unit Testing Best Practices: 9 Ways to Make Unit Tests Shine. Retrieved from https://brightsec.com/blog/unit-testing-best-practices/
Razorops. (n.d.). Streamlining Kubernetes workflows: The power of CI/CD integration. Retrieved from https://razorops.com/blog/streamlining-kubernetes-workflow-power-of-cicd-integration
Rickard, M. (n.d.). An Overview of Docker Desktop Alternatives. Retrieved from https://matt-rickard.com
Softude. (2023). Unit Test vs Integration Test: What is Better for QA Professionals?. Retrieved from https://www.softude.com/blog/unit-test-vs-integration-test-what-is-better-for-qa-professionals
TechWorld with Nana. (2020, November 6). Kubernetes Tutorial for Beginners [FULL COURSE in 4 Hours] [Video]. YouTube. https://www.youtube.com/watch?v=X48VuDVv0do
Technical Ustad. (n.d.). 5 Best Minikube Alternatives For Local Kubernetes Testing. Retrieved from https://technicalustad.com
Wikipedia. (2024). Data transfer object. In Wikipedia, The Free Encyclopedia. Retrieved from https://en.wikipedia.org/wiki/Data_transfer_object
Zaira Hira. (2019). Kubernetes VS Docker Swarm – What is the Difference?? Retrieved from https://www.freecodecamp.org/news/kubernetes-vs-docker-swarm-what-is-the-difference/